The mmult Algorithm
The application in this tutorial performs the following calculation:
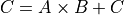
A, B, and C are double-precision square matrices. The parallel algorithm
employed has one main process (MPI rank 0) that splits this calculation up and
distributes the work across several worker processes. The application performs the
following tasks:
The master process initializes matrices
A,B, andC.The master process sends the entire matrix
B, along with slices ofAandC, to the worker processes.The master and worker processes perform the matrix multiplication function on the domain that has been given to the processes, and each process computes a slice of
C.The master process retrieves all slices of
Cand puts the results into matrixC.The master process writes the results of
Cin a file.
Fig. 7 shows how all processes contribute in parallel to the
creation of the result in matrix C.
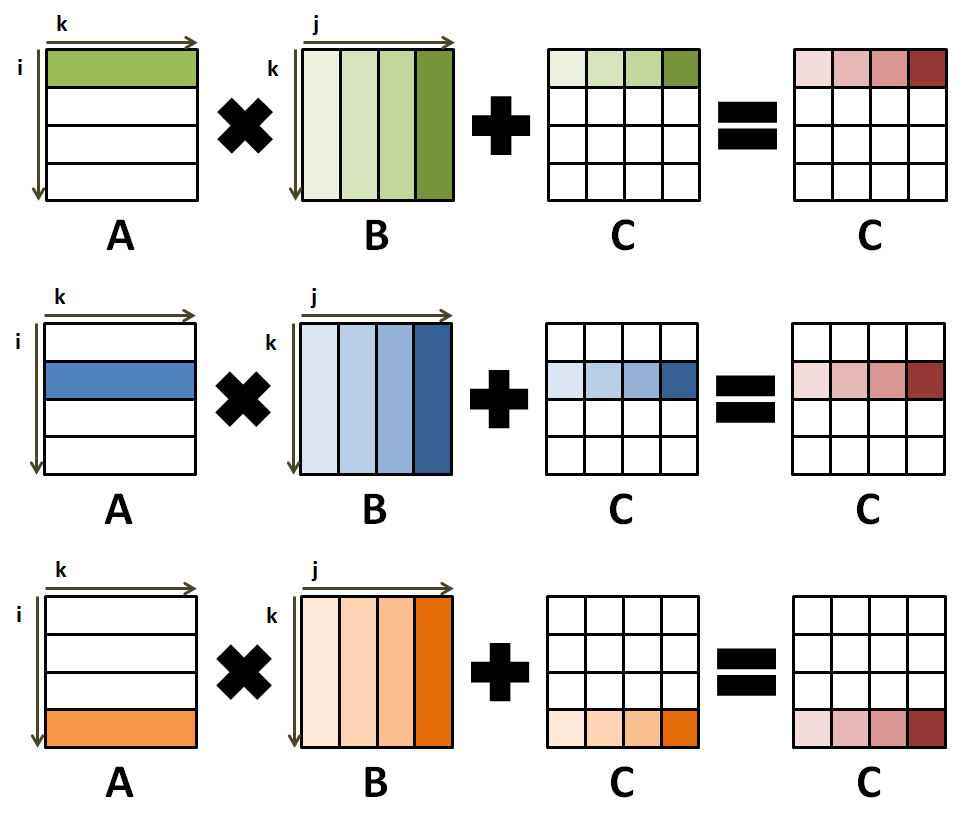
Fig. 7 Description of the parallel algorithm
C/C++, Fortran, and Python versions of this application can be found in the examples/
directory of your Linaro Forge installation, see the files named mmult*.