Optimize the code with vectorization
Describes how to iteratively optimize the vectorization example code with vectorization, and profile it with Linaro MAP.
Prerequisites
You must install all the necessary tools as described in Software requirements.
Procedure
Begin with the first failed vectorization attempt. According to the compiler remark annotation in Fig. 15, the compiler is unable to identify the array bounds so vectorization was not possible.
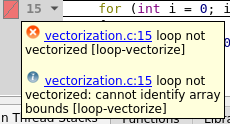
Fig. 15 Compiler remark for a failed vectorization attempt due to unknown array bounds
Assist the compiler by clarifying the bounds:
for (int i = 0; i < num/2; i++) { arr2[2*i] = 3.0f * arr1[i]; arr2[2*i+1] = 3.0f * arr1[i]; }
Compile the application by running make, and profile with Linaro MAP:
make -f vectorization.makefile map ./vectorization
Notice in Fig. 16 that the vectorization attempt is now successful, and that the runtime of the program has been reduced.

Fig. 16 Compiler remark for a successful vectorization attempt after providing array bounds
Next focus on the failed vectorization attempt at the nested loop. The compiler has deemed vectorization to be non-beneficial due to the non-sequential memory accesses in this loop (see Fig. 17).

Fig. 17 Compiler remark for a failed vectorization attempt due to non-sequential memory accesses
Optimize the performance of this loop by interchanging the loop conditions.
for (int j = 0; j < cols; j++) { for (int i = 0; i < rows; i++) { z[j * cols + i] = x[j * cols + i] - y[j * cols + i]; } }
Compile and profile the application again. Notice that the vectorization attempt is now successful in Fig. 18, and that the runtime of the program has been reduced.
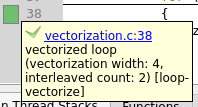
Fig. 18 Compiler remark for a successful vectorization attempt after interchanging loop conditions
Now focus on the final failed vectorization attempt (Fig. 19). This loop contains a loop-carried dependency, i.e. the result of one iteration is dependent on another.
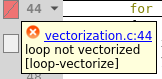
Fig. 19 Compiler remark for a failed vectorization attempt due to a loop-carried dependency
It cannot be fully vectorized, but it can be distributed into vectorizable and unvectorizable parts as follows:
for (int i = 1; i < size; i++) { x[i] = x[i - 1] * y[i - 1] - z[i]; y[i] = 2.0f * y[i - 1]; } for (int i = 1; i < size; i++) { z[i] = x[i] + y[i]; }
Compile and profile the application again. Although the compiler has vectorized the second distributed loop in Fig. 20, depending on your system the runtime of the program may have increased due to the introduction of another loop.
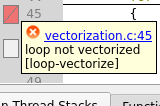
Fig. 20 Compiler remarks showing both a failed and a successful vectorization attempt after distributing the loop
This shows that acting upon all failed compiler optimization remarks may not always be beneficial. Revert the last change to optimize the runtime of the program if that is the case.