Optimize the application job with thread affinities
Describes how to iteratively optimize the performance of a SLURM job running the wave_openmp example code using the Thread affinity advisor.
Prerequisites
You must install all the necessary tools as described in Software requirements.
Procedure
Examine the first two commentary items:
[ERROR] node-1 (1 similar), ranks 0-1: No bindings set for threads 238507-238508,238545-238558 from processes 238507-238508. [ERROR] node-1 (1 similar), ranks 0-1 (processes 238507-238508) overlap with at least one other process e.g. processes 238507 and 238508
Click the
0-1hyperlink to select ranks 0 and 1 under Processes and threads. Notice that compute threads from both processes are listed and that they are all bound to logical CPUs 0-7 on the 8 core node (i.e. there are no particular bindings set for these threads):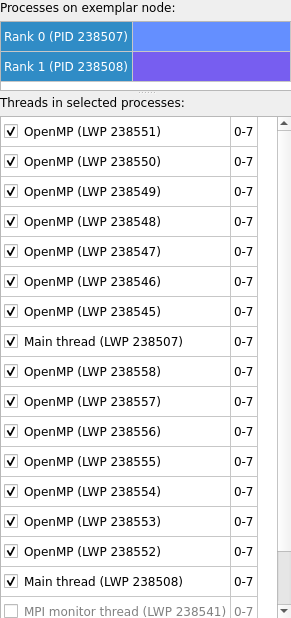
This is problematic, because threads spanning NUMA nodes severely impacts performance:
[ERROR] node-1 (1 similar), ranks 0-1 (processes 238507-238508) spans multiple NUMA nodes e.g NUMA nodes 0 and 1 [ERROR] node-1 (1 similar), ranks 0-1 (processes 238507-238508) contain at least one thread spanning multiple NUMA nodes e.g 238508 over NUMA nodes 0 and 1
Click on a single thread to see this in the Node topology viewer:
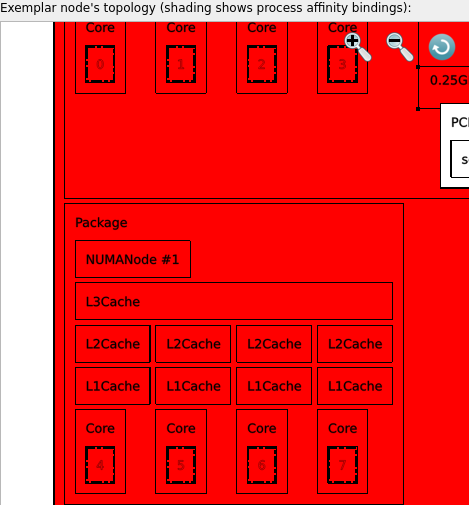
Click on a single logical CPU to highlight all threads that are bound to it.
Resolve these issues by running the SLURM job and binding each rank to a single socket (in this case, NUMA node):
map srun --ntasks-per-node=2 --cpu-bind=sockets ./wave_openmp
Notice that the performance of the application has been greatly improved:
points/second: 2804.2M (175.3M per process)
Open the Thread affinity advisor dialog to see that each rank is bound to a single NUMA node:
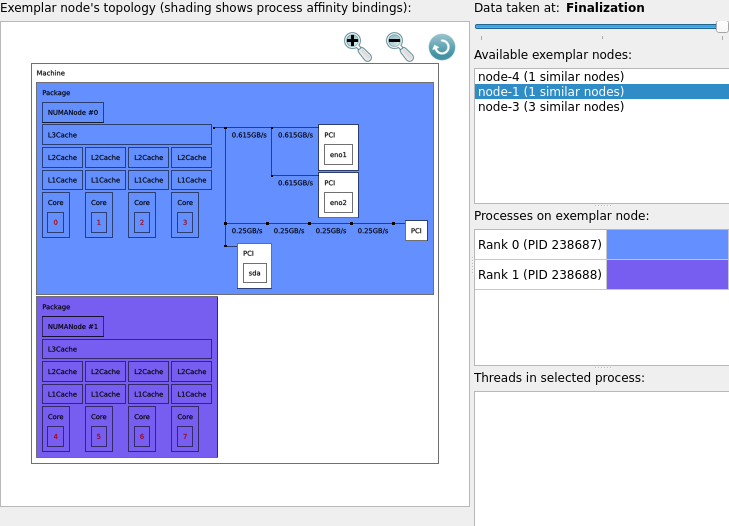
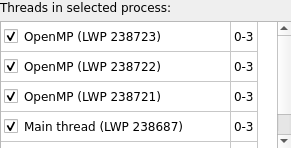
Click on rank 0 under Processes and threads to verify that each of its compute threads is bound to NUMA node 0:
Resolve the remaining commentary item by binding a single compute thread to each logical core. With the GNU C/C++/Fortran Compiler, this is accomplished by setting
GOMP_CPU_AFFINITY=0-7in the environment:GOMP_CPU_AFFINITY=0-7 map srun --ntasks-per-node=2 --cpu-bind=sockets ./wave_openmp
Notice that the Thread affinity advisor tool button no longer indicates thread affinity issues:

Open the Thread affinity advisor dialog to see that the commentary is empty.
Select rank 0 to show that each compute thread is uniquely bound to a single logical CPU:
Notice that the performance of the application has not improved:
points/second: 2803.1M (175.2M per process)
In this scenario, the kernel was able to schedule threads within each NUMA node so that the application could be performant. Acting on every thread affinity issue may be unnecessary.