Accelerator
NVIDIA
The NVIDIA CUDA metrics are enabled if you have Arm® Forge Professional. Contact Arm support for upgrade information at: support-hpc-sw@arm.com.
Note
Accelerator metrics are not available when linking to the static Arm® MAP sampler library.
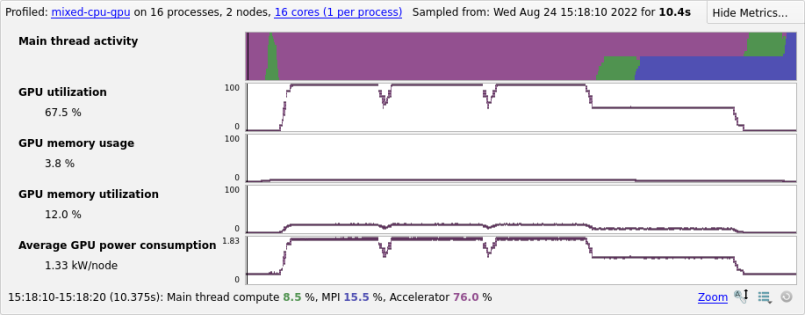
- GPU utilization
Percent of time that the GPU card was in use, that is, one or more kernels are executing on the GPU card. If multiple cards are present in a compute node this value is the mean across all the cards in a compute node. Adversely affected if CUDA kernel analysis mode is enabled.
See CUDA Kernel analysis.
- GPU memory usage
- The memory allocated from the GPU frame buffer memory as a percentage of the total available GPU frame buffer memory.
- GPU memory transfers
Metrics summarizing CUDA memory transfers are available for CUDA 11+ programs, including heterogeneous workloads where some processes use GPUs and others do not.
Three categories of metric are available:
Byte Transfer Rate: Bytes transferred per second per process.
Memory Transfer Rate: Transfers per second per process.
Time Spent in Memory Transfers: Proportion of time in transfers per process.
Note
If a very large number of memory transfer events occur in the program, the time spent in memory transfers metric might only provide an approximation.
Different types of memory transfer can occur in the program you are profiling. For example, the program can transfer data between host memory and GPU device, or between different GPU devices on the host. Six memory transfer types are available within each category:
- Host to Device
- A host to device memory copy.
- Device to Host
- A device to host memory copy.
- Device to Device
- A device to device memory copy on the same device.
- Host to Host
- A host to host memory copy.
- Peer to Peer
- A peer to peer memory copy across different devices.
- Off-device
Sum of host-to-device, device-to-host, and peer-to-peer types (everything using PCIe or NVLink).
Selecting the category using the mechanism displays the relevant metrics for all memory transfer types occurring within the program.
AMD
The AMD ROCm metrics are enabled if you have a Arm® Forge licence with ROCm support. Contact Arm support for upgrade information at: support-hpc-sw@arm.com.
Note
Accelerator metrics are not available when linking to the static Arm® MAP sampler library.
- GPU utilization
- Percent of time that the GPU card was in use, that is, one or more kernels are executing on the GPU card. If multiple cards are present in a compute node this value is the mean across all the cards in a compute node.
- GPU memory usage
- The memory allocated from the GPU Video RAM (VRAM) as a percentage of the total available GPU memory VRAM.
- GPU memory utilization
- Percentage of time that the GPU memory was in use. If multiple cards are present in a compute node, this value is the mean across all the cards in a compute node.